Java 序列化机制是一种将对象转换为字节流的过程,以便在网络上传输或保存到文件中,并能在需要时将字节流还原为对象。这一机制通过实现 java.io.Serializable 接口来实现,同时涉及到一些关键概念和注意事项。
# Serializable 接口
Serializable 接口是 Java 提供的标记接口,没有包含任何需要实现的方法。实现了这个接口的类表明其对象是可序列化的,可以被转换为字节流。
public interface Serializable {
}
通过实现 Serializable 接口,标识类的对象可以被序列化。这使得对象可以在网络上传输或保存到文件中,而不失去其状态和结构。
# 序列化过程
序列化是将对象的状态(字段值)转换为字节流的过程。这个过程由 ObjectOutputStream 类来完成。序列化使得对象可以以字节流的形式进行存储或传输,便于在不同系统之间进行数据交换。如下我们列举几个重要的方法的源码:
writeObject方法
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}
enableOverride 表示是否启用了对象写入的覆盖机制。如果启用,会调用 writeObjectOverride 方法来执行对象的特定写入逻辑。
如果没有启用覆盖机制,则调用 writeObject0 方法执行实际的对象序列化。
writeObject0 方法负责处理对象的序列化,其中第二个参数 false 表示不使用不共享的方式进行序列化。
如果在序列化过程中抛出 IOException 异常,会捕获该异常。如果当前深度为0(表示不在嵌套序列化过程中),则调用 writeFatalException 方法来处理异常,否则将异常重新抛出。
- writeObject0
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
// check for replacement object
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
break;
}
cl = repCl;
}
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
// if object replaced, run through original checks a second time
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
// remaining cases
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}
# 反序列化过程
当需要从字节流中恢复对象时,Java 序列化机制会将字节流还原为对象的状态。这个过程由 ObjectInputStream 类来完成。如下我们列举几个重要的方法的源码:
- readObject()
private final Object readObject(Class<?> type)
throws IOException, ClassNotFoundException
{
if (enableOverride) {
return readObjectOverride();
}
if (! (type == Object.class || type == String.class))
throw new AssertionError("internal error");
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(type, false);
handles.markDependency(outerHandle, passHandle);
ClassNotFoundException ex = handles.lookupException(passHandle);
if (ex != null) {
throw ex;
}
if (depth == 0) {
vlist.doCallbacks();
}
return obj;
} finally {
passHandle = outerHandle;
if (closed && depth == 0) {
clear();
}
}
}
这段代码的主要作用是根据给定的类型 (type) 进行对象的反序列化。在这个过程中,它使用了一些状态变量,如 enableOverride、passHandle、handles、depth、vlist 等,来管理反序列化的过程。在处理嵌套对象时,它通过 markDependency 方法标记了当前对象与封闭对象的依赖关系。在深度为 0 时,执行了clear方法。具体反序列化执行的核心方法是readObject0()
- readObject0()
private Object readObject0(Class<?> type, boolean unshared) throws IOException {
boolean oldMode = bin.getBlockDataMode();
if (oldMode) {
int remain = bin.currentBlockRemaining();
if (remain > 0) {
throw new OptionalDataException(remain);
} else if (defaultDataEnd) {
/*
* Fix for 4360508: stream is currently at the end of a field
* value block written via default serialization; since there
* is no terminating TC_ENDBLOCKDATA tag, simulate
* end-of-custom-data behavior explicitly.
*/
throw new OptionalDataException(true);
}
bin.setBlockDataMode(false);
}
byte tc;
while ((tc = bin.peekByte()) == TC_RESET) {
bin.readByte();
handleReset();
}
depth++;
totalObjectRefs++;
try {
switch (tc) {
case TC_NULL:
return readNull();
case TC_REFERENCE:
// check the type of the existing object
return type.cast(readHandle(unshared));
case TC_CLASS:
if (type == String.class) {
throw new ClassCastException("Cannot cast a class to java.lang.String");
}
return readClass(unshared);
case TC_CLASSDESC:
case TC_PROXYCLASSDESC:
if (type == String.class) {
throw new ClassCastException("Cannot cast a class to java.lang.String");
}
return readClassDesc(unshared);
case TC_STRING:
case TC_LONGSTRING:
return checkResolve(readString(unshared));
case TC_ARRAY:
if (type == String.class) {
throw new ClassCastException("Cannot cast an array to java.lang.String");
}
return checkResolve(readArray(unshared));
case TC_ENUM:
if (type == String.class) {
throw new ClassCastException("Cannot cast an enum to java.lang.String");
}
return checkResolve(readEnum(unshared));
case TC_OBJECT:
if (type == String.class) {
throw new ClassCastException("Cannot cast an object to java.lang.String");
}
return checkResolve(readOrdinaryObject(unshared));
case TC_EXCEPTION:
if (type == String.class) {
throw new ClassCastException("Cannot cast an exception to java.lang.String");
}
IOException ex = readFatalException();
throw new WriteAbortedException("writing aborted", ex);
case TC_BLOCKDATA:
case TC_BLOCKDATALONG:
if (oldMode) {
bin.setBlockDataMode(true);
bin.peek(); // force header read
throw new OptionalDataException(
bin.currentBlockRemaining());
} else {
throw new StreamCorruptedException(
"unexpected block data");
}
case TC_ENDBLOCKDATA:
if (oldMode) {
throw new OptionalDataException(true);
} else {
throw new StreamCorruptedException(
"unexpected end of block data");
}
default:
throw new StreamCorruptedException(
String.format("invalid type code: %02X", tc));
}
} finally {
depth--;
bin.setBlockDataMode(oldMode);
}
}
# serialVersionUID
serialVersionUID 是用于版本控制的序列化版本号。它是一个长整型数值,用于标识类的版本。通过显式声明 serialVersionUID,可以在类结构发生变化时依然能够正确地进行反序列化。
@Data
public class LoginUserInfo implements Serializable {
private static final long serialVersionUID = 1L;
...
}
如果在类中没有明确声明 serialVersionUID,Java 运行时系统会根据类的结构自动生成一个。这种自动生成的 serialVersionUID 是基于类的各个方面的,包括字段、方法、父类等。如果类的结构发生变化,可能导致自动生成的 serialVersionUID 发生变化。这可能会导致在反序列化时,类的版本不一致,从而导致 InvalidClassException 异常。
所以显式声明 serialVersionUID是确保反序列化过程正确的关键,避免因类结构变化而导致的问题。
# transient 关键字
关键字 transient 用于标记字段,表示在对象序列化的过程中,这个字段应该被忽略。例如,如果一个类有一个不希望被序列化的缓存字段,可以使用 transient 关键字来避免将其写入序列化数据。例如ArrayList、LinkedList 等类中的一些属性就是使用transient修饰的:
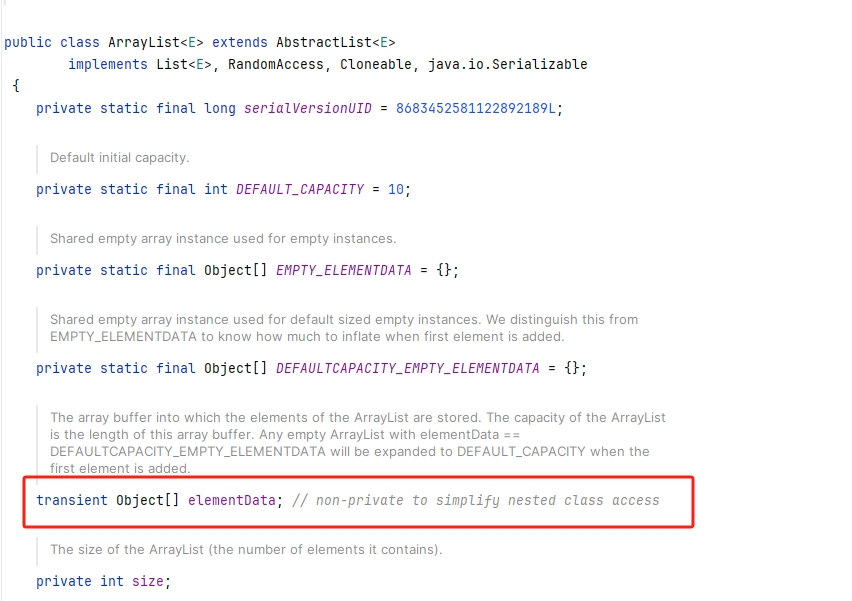
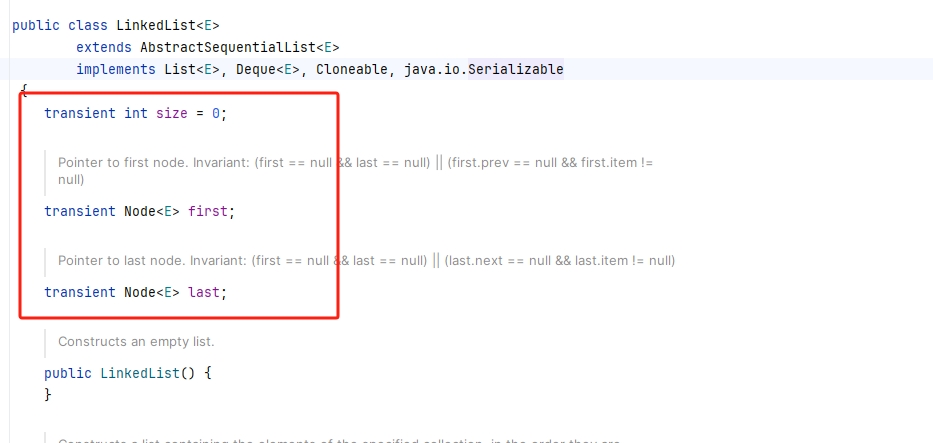
# 自定义序列化和反序列化
有时候,可能需要自定义序列化和反序列化的过程以满足特定需求。可以通过实现 writeObject 和 readObject 方法来实现自定义逻辑。如ArrayList类中就是通过自定义的序列化和反序列化方法:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
# 序列化不保存静态变量
- 对象状态 vs. 类状态
序列化的主要目的是保存对象的状态,即对象的实例变量。静态变量是类级别的,它们对于每个对象实例都是相同的。序列化关注的是对象的实例状态,因为这是对象在不同环境中重建时所需的关键信息。
- 节省空间
静态变量通常用于表示类级别的常量或共享数据,这些数据在所有对象实例之间是相同的。如果每个对象的静态变量都被序列化并存储,将导致冗余,浪费存储空间。序列化的目标之一是尽可能紧凑地保存对象的状态,因此不保存静态变量是一种优化。
- 不需要还原
静态变量在类加载时初始化,并在整个应用程序的生命周期内保持不变。因此,在反序列化时不需要重新初始化静态变量。序列化和反序列化的目标是保存和还原对象的动态状态,而不是类级别的静态状态。
# 序列化的安全性和性能考虑
在实际应用中,需要注意序列化的安全性和性能。反序列化过程中可能存在安全风险,因此要谨慎处理来自不受信任源的序列化数据。此外,对于大量数据的序列化,可能会影响系统性能,可以考虑使用更高效的序列化工具或压缩算法。
# 总结
综合来看,Java 序列化的核心思想是将对象的状态转换为字节流,并通过 ObjectOutputStream 类完成这一过程。该类在内部处理了对象引用的记录、对象字段的写入、自定义写入方法的执行等。在实际应用中,我们需要注意序列化版本控制、对象字段的 transient 关键字的处理以及序列化性能等方面的问题。
请注意,Java 序列化机制在现代应用中可能会遇到一些挑战,包括性能问题、安全性问题以及与其他语言的兼容性等。因此,在一些场景下,开发者可能会考虑使用其他序列化框架,如 JSON 或 Protocol Buffers,以满足不同的需求。